Bias in Natural Language Processing @EMNLP 2020
In this article, I am listing out most of the papers related to the discovery and mitigation of bias in NLP models, which were accepted in EMNLP 2020. I have divided these papers into three major categories alongside a separate category of all the new datasets released in these papers. And if you are looking for a quick overview, then head over to the TL;DR section 😅. I have listed all the papers mentioned in the blog along with a one-two line summary.

- Discovery of Bias
1.1 Gender Bias
1.2 Political Bias
1.3 Annotator Bias
1.4 Multiple - Mitigating Bias
2.1 Task Specific
2.2 Embeddings - Miscellaneous
- TL;DR
- Datasets
Before I begin the recap, I would like to remind readers that the post contains potentially offensive examples and should be taken in context. Additionally, I've copied some sentences from the papers, since who'd better explain the concepts than the author themselves. 😇.Discovery of Bias
In this section, I will discuss papers that either present a method to discover or quantify bias in the text, dataset, or the model itself.
Gender Bias
The first paper on our list is by Dinan et al. They argue
no extant work on classifying gender or removing gender bias has incorporated facts about how humans collaboratively and socially construct our language and identities.

They propose a new framework where each dialogue/sentence has a gender annotation along three dimensions (i) gender of the person speaking (As), (ii) gender of the person to which the dialogue/sentence is spoken to (To) and, (iii) the gender of the subject i.e., the person who is being spoken about in the dialogue (About). This decomposition enables a finer-grained understanding of bias and better classification of gender’s effects on text from multiple domains.
Application 🚨 : A classifier trained on this data can be then used to annotate dialogue dataset along these three axes. Then, a bot trained to incorporate, these annotations can reply to a query by assuming personas and also change the reply based on who the bot is talking to and the gender of the subject.
On the topic of gender bias, Monarch et al., find
for 20 years the major part-of-speech (POS) taggers and parsers missed that “hers” and “theirs” were pronouns, but it had gone unreported
They find that these biases are amplified in the current generation of the language models. The models predict a subset of the independent genitive pronoun with less frequency than expected given the training data. To showcase this bias, they employ a multi-step process to generate sentences where at the end of the process, LM is asked to fill in the correct pronoun. Bias is calculated based on the ratio between the relative probabilities of “hers”, “his” or “theirs” in the softmax output. They found that for 103/104 attributes, “his” was preferred over“hers” or “theirs” 🧐.
Just relying on humans to identify gender bias in a sentence is expensive and can have unwanted bias in the annotation. To circumvent it, Field et al. propose an unsupervised approach to identify gender bias against woman.

Their objective is to detect gender bias in COM_TXT that happens because of W_GEN. They hypothesize that a classifier that does not rely on the artifacts produced in the data due to O_TXT, W TRAITS, and other overt signals, but can still predict the gender from COM_TXT. Then COM_TXT contains biased text. Following are the steps they take to control the effect of O_TXT, W_TRAITS, and overt signals.
- O_TXT: They employ propensity matching to remove data points from the dataset for which the O_TXT is heavily associated with one gender.
- W_TRAITS: For each COM_TXT they obtain a vector whose elements represent p(k|COM_TXT_i), and the dimensionality is the number of OW individuals in the training set. Here k represents OW. At training time, the adversary network should not be able to predict this vector, while the other classifier predicts the gender.
- Overt signals: They replace gendered terms with more neutral language, for example woman → person and man → person.
One of the pioneering works in bias mitigation in word embeddings is by Bolukbasi et al., where they remove each word’s gender projection on a pre-defined gender direction. In a simplistic setting, gender direction can be calculated via \vec{he} — \vec{she}. However, Bolukbasi et al. take the assumption that the subspace which captures gender bias is linear. Vargas et al. question this assumption by evaluating over kernelized, non-linear version of the subspace. They begin by proving that the Bolukbasi et al. method is equivalent to PCA on a specific design matrix. Note that this was also alluded by Bolukbasi et al. but is proven more formally by them. Then they transform this PCA to a kernel PCA using the idea introduced by Scholkopf et al. Thus transforming the space into a non-linear one.
Interestingly, they find that there is no significant performance difference between the non-linear bias mitigation technique and the linear one. Non-linear WEAT evaluation is on par with linear one as well as the similarity task (Simlex-999). Thus
We conclude that much of the gender bias in word embeddings is indeed captured by a linear subspace
Gonzalez et al. released a multi-task, multi-lingual challenge set with a specific focus on languages where anti-reflexive possessive pronouns are gendered, but reflexives are not. This phenomenon can be found in some Scandinavian, Slavic, and Sino-Tibetan languages. They employ this characteristic of the language to unmask gender bias in several ways.
For example while translating “mekanikeren har brug for sine.REFL værktøjer til at arbejde” into English the model will have to choose between two possible, correct translation:

The extent to which models translate English source sentences with possessive masculine or feminine pronouns into target sentences with reflexive pronouns gives an idea about the bias in the model. In their analysis:
We find evidence for gender bias across all task-language combinations and correlate model bias with national labor market.
Political Bias
Moving from gender bias, Baly et al. propose a method to predict political bias in an article. In their analysis they find that a naive classifier learns to associate the article’s source with the ideology rather than its actual content. To showcase this, they create a new media-based split, where all articles from a particular media source would only exist in one of the train/test/valid split. This form of splitting leads to very low accuracy. They circumvent this problem to some extend by domain adaptation training and triplet loss-pretraining. Chen et al. also answer a similar question alongside analysis of how sentence position and other article attribute correlates with bias.
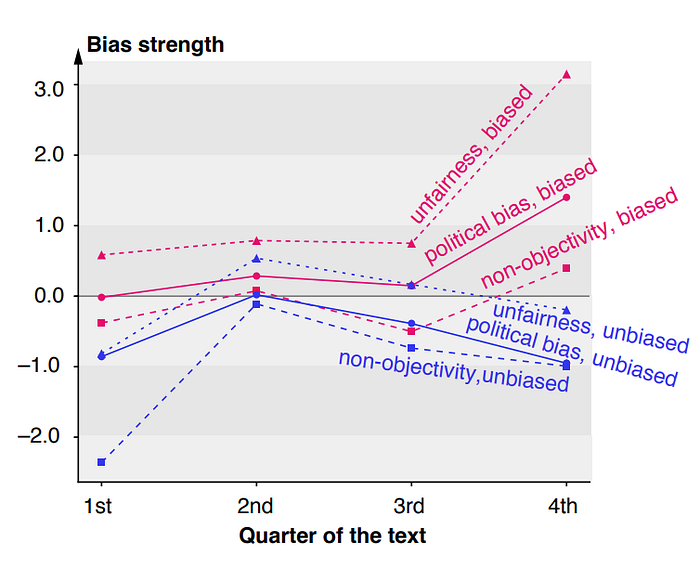
Another paper by Chen et al. answer the question of how political bias manifests itself linguistically. To do so, they employ an RNN based classifier and reverse feature analysis to find bias patterns. A few of the interesting observations they find are:(i) Last paragraphs are the most biased ones, specifically the last two sentences. (ii) Most biased articles begin with a neutral tone, and (iii) they tend to use emotional and opinionated words such as “disappoint,” “trust,” and “anger.”
Gupta et al. propose LM based method to generate biased news (i) from scratch, including titles and other meta data, and (ii) changing the bias of a given seed article. In both scenarios, the generated new is fake. However, in a few cases, specifically the second scenario, the generated news article might have some similarity with seed text. A subjective evaluation showed that the generated news is fluent, with few participants even confirming that the bias is easily visible.

In seminal work by Boydstun et al., they suggested 15 broad frames to analyze how issues are framed in news media. These frames included topics like economic, morality, etc. They argue that these frames capture ideological split, and thus. However, Roy et al. argue that these frames are too coarse. For example, in the image on the left, the same issue is also framed from an economic perspective. To circumvent this issue, they propose a more fine-grained analysis. Specifically, they propose a three-step approach.
- Extending Frame Lexicon: They begin the process by annotating paragraphs with policy frames using lexicon matches and then extract repeating phrases (using bigrams and trigrams) occurring in these paragraphs.
- Identification of Subframes: Ask humans to group these repeating phrases to subframes in a manner representing political talking points.
- Weakly Supervised Categorization of Subframes: Train an embedding model so as to capture the same space as the text associated with the subframes. This enables the capturing of these subframes in the new text.
Annotator Bias
Hate speech annotation is often subjective and can lead to bias in training data. This bias in the training data can severely affect the performance of a hate speech classifier and might make the classifier unfair toward some demographics. The effect of this annotator bias is shown in this EMNLP by Kuwatly at al. and Wich et al. They both find that a classifier trained on data annotated by a specific demographic performed significantly worse on the same test data annotated by crowd workers with some other demographics. A primary difference between the works was that Kuwatly et al. relies on demographic attributes available in the dataset. On the other hand, Wich et al. employs a community detection-based algorithm to group annotators.
Multiple
In this subsection, I am listing papers that are generally trying to tackle multiple stereotypes. That said, many of the above approaches can also be used for discovery, but they primarily focused on the discovery of gender bias.

Li et al. present a framework to probe and quantify biases through underspecified questions. The questions don’t have an obvious answer, and thus the answer generated by the model would indicate stereotyping bias. However, naively using the score of the model as bias would be incorrect due to two forms of reasoning errors namely:
- Positional Dependence: Prediction of the QA model heavily depends upon the order of the subject, even if the content remains unchanged.
- Attribute independence: Prediction of the QA model does not depend on the content of the question itself. Even negating the question doesn’t change the answer.
They provide mechanisms to assign a score to the model’s biasness while taking these reasoning errors into account.
Our broad study reveals that (1) all these models, with and without fine-tuning, have notable stereotyping biases in these classes; (2) larger models often have higher bias; and (3) the effect of fine-tuning on bias varies strongly with the dataset and the model size.
With a similar aim of quantifying biases in LMs, Nangia et al. introduces benchmark, Crowdsourced Stereotype Pairs benchmark (CrowS-Pairs). The benchmark/challenge set aims to measure nine kinds of social bias present in the language models against protected demographic groups in the US. Specifically, the data set consists of 1508 examples. Each example contains two sentences, with one being more stereotyping when compared to others. Some of the samples from the paper:

They find that three commonly used MLM (ALBERT, RoBERTa, BERT) substantially favors sentences that express stereotypes in every category in CrowS-Pairs. Interestingly, all models had comparatively higher bias scores in the religion category while had a lower bias score in the gender and race categories.
Zhao at al. argues that corpus level bias evaluation doesn’t paint the complete picture of the biasness of the embedding model. For example, the toxicity classifier for sentences mentioning black and white race groups is 4.8%. This gap is only marginally larger than the performance gap of 2.4% when evaluating the model on two randomly split groups. However, in the sentences containing the token “racist”, the performance gap between these two groups is as large as 19%.
To identify these local biases, the authors proposed a clustering-based algorithm, LOGAN. They aim to cluster such that (1) similar examples are grouped together, and (2) each cluster demonstrates local group bias. To do so, they have two primary objectives (i) Clustering objective derived from standard clustering algorithms such as KNN to cluster similar examples and (ii) Local group bias loss, which tries to form clusters that maximize a specific bias metric within the cluster.
Mitigating Bias aka Debiasing
I have divided this section into two sub-sections namely (i) Task specific where I discuss methods which have been proposed in a context of a specific task such as language generation , and (ii) Embeddings which as the name suggests specifically focuses on debiasing word representations.
Task Specific
Most of the work in task-specific was related to identifying bias and debiasing dialogue systems. A common theme for mitigation, or at least as a baseline, was counterfactual data generation, not only in task-specific but also across the board.
For example, Zueva et al. find that Russian hate speech classifier often triggered due to the presence of certain words like black, jew, or женщина, even when the text was not toxic. To counter these biases, they propose to augment the dataset by generating positive examples via a Transformer LM trained on normative Russian text such as news and fairy tales. Additionally, while training the classifier, they replace words from a list of protected identities (like nationalism, homophobia) with <UNK> token. To further improve the classifier, they add an auxiliary task of predicting the protected identity from the original text. Using data augmentation and auxiliary task loss, they showcase an absolute gain of 6 F1 points.
Dinan et al. analyzes gender bias in several existing dialogue dateset and proposes a three step mitigation strategy namely:
- Counterfactual Data Augmentation where they add new examples to the dataset by swapping the gender of the existing examples.
- Positive-Bias Data Collection where they crowd source new examples with explicit focus on bias. The crowd workers are asked to manually swap gender and write additional diverse personas.
Even with explicit instruction, annotators created 3 times as many male characters as female characters, revealing the stubbornness of the inherent gender biases of the available crowdworker pool 🤯.
- Bias control training where they forced model to associate a special token with the genderedness of the dialogue response. This enabled authors to control the genderness of the generated response at inference time.
They evaluate their strategy over LIGHT dataset, which they found to be the most biased in their in-depth analysis.

Debiasing methods developed for word embeddings, Liu et al. argue, don’t work well for dialogue systems. These methods force the dialogue model to generate similar responses for different genders. To counteract it and at the same time generate a non-biased response, they propose a disentanglement model alongside an adversarial learning framework to generate responses with unbiased gender features and without biased gender features. For instance, in the response “she is an actress and famous for her natural beauty”, “actress” is an unbiased gender feature for females. In contrast, for the response, “I’m sure she’s a little jealous,” the word “jealous” is a biased gender feature under the context.
The disentangled model generates two representations (i) unbiased gender features and (ii) remaining semantic features, including biased gender features. These two features are fed to two discriminators D1 and D2 respectively, to predict the gender of the dialogue. The objective of adversarial training is to produce an unbiased response such that 1) its unbiased gender features can be used to correctly predict the gender of the dialogue by D1; 2) D2 cannot distinguish the gender. They find that their methods produce much more diverse and engaging responses than data augmentation and word embedding regularization based methods.
On the lines of Bias control training, Sheng et al. propose an adversarial trigger phrase search-based method to influence the generated text’s bias polarity. The image below shows an overview of their work.

They employ the trigger method to both positively and negatively influence the bias of generated text. The image below shows their automatic evaluation results using a regard classifier, which classifies generated text into three categories (positive, negative, neutral).

Moving away from the dialogue system, in the land of translation, Stafanovics et al. propose an approach to improve translation from non-grammatical gender to gender ones.
When translating “The secretary asked for details.” to a language with grammatical gender, it might be necessary to determine the gender of the subject “secretary”. If the sentence does not contain the necessary information, it is not always possible to disambiguate. In such cases, machine translation systems select the most common translation option, which often corresponds to the stereotypical translations, thus potentially exacerbating prejudice and marginalisation of certain groups and people.
To circumvent it, the authors propose to annotate source word with target gender. At training time, they first tag target sentence words with a gender- F for female, M for male, N for neutral, and U for cases where grammatical gender is not available. Then this information is projected back to the source words. Additionally, to ensure that the model performs well even in the absence of the annotation, they randomly replace actual annotation with U. At inference, they employ co-reference to find the source sentence’s referential gender information.
Embeddings
Based on the observation by Gonen et al. that the existing debiasing methods are unable to completely debias word embeddings because the relative spatial distribution of word embeddings after the debiasing process still encapsulates bias-related information. Kumar et al. propose a method which aims to minimize the projection of gender-biased word vectors on the gender direction and at the same time reduces the semantic similarity with neighbouring word vectors having illicit proximities. Specifically, they employ a multi-objective optimization function with three major components:
- Repulsion: The objective function aims to repel the given word from the neighboring word vectors which have high value of indirect bias.
- Attract: which aims to minimize the loss of semantics between the given word vector and it’s debiased counterpart.
- Neutralization: which aims to minimize its bias towards any particular gender.
Alongside, they also propose a new metric Gender based Illicit Proximity Estimate (GIPE) with the motivation of “estimating the gender based proximity bias at global level”.
Shin et al. present a latent disentanglement model alongside counterfactual generation to debias word embeddings. The transform embedding of each word to two different spaces, one representing gender while another representing the semantic content. They do so by prohibiting inference on the gender latent information from the semantic information. Then, they generate a counterfactual word embedding by converting the encoded gender latent into the opposite gender. The counterfactual embeddings are generated via regularizing the vector representing the gender such that the classifier, which predicts the gender switches its prediction. They then align the counterfactual word embeddings with original word embeddings via a kernel function, which finally forms a gender neutral embeddings. This method shows lower performance degradation in the downstream task as well as perform well on WEAT.
Moving from word embedding to knowledge graph embeddings, Fisher et al. propose an adversarial loss-based training mechanism to de-bias them. Akin to previous methods, they define a set of “sensitive attributes” human characteristics such as religion and gender, which may be associated with unwanted stereotypes.
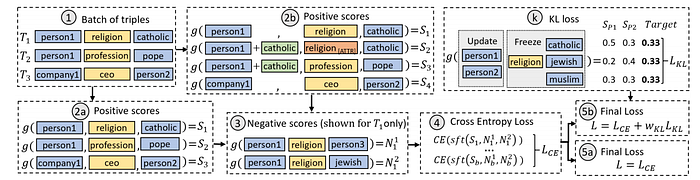
While training, they extract all human entities’ embeddings in the batch and calculate these entities’ score with each sensitive relation for each of the top M most frequent objects. Then they force the model to have an equal probability for each of these objects using KL divergence by changing the embedding of human entities. It causes the model to remove information from them, which can predict this sensitive information. They also have a simple mechanism to add this information back, if needed. Using this training mechanism, they achieve a substantial decrease in the training time compared to other methods and maintain near optimum accuracy.
Ma et al. propose a masked language model based mechanism to rewrite bias of a sentence. They
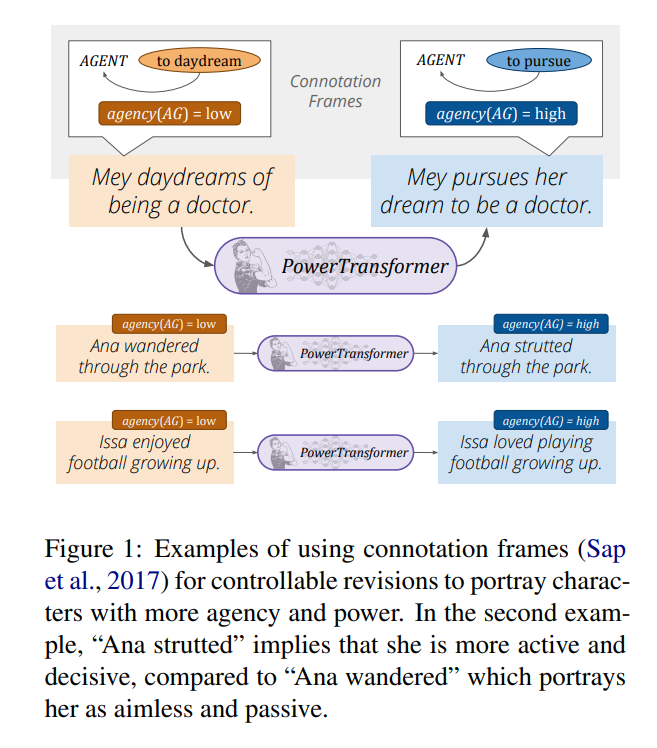
study the portrayal biases through the lens of connotation frames of power and agency (Sap et al.), which provide pragmatic knowledge about implied power and agency levels projected onto characters by a predicate.
For more details, Maarten, one of the authors of the paper, wrote an excellent blog that summarizes all the contributions of the paper.
Miscellaneous
I will describe a few papers which I found interesting but do not fit well with the above categories. They are papers that are using techniques to quantify bias in auxiliary tasks.
Schmahl et al. propose an embedding based technique to understand the change of gender bias in Wikipedia. Specifically, they train a word2vec model over different time snapshots of Wikipedia and then apply the Word Embedding Association Test to see how bias these embeddings are. Through their analysis, they found that in a few categories like family and science, though with a caveat, the bias has indeed decreased. Moreover, these changes are specifically more pronounced in recent articles. However, in categories like Art, bias has significantly increased.


Parallel to Schmahl et al., Gala et al. develop a method to analyze gender bias in narrative tropes. They collected data from tvtropes.com and computed genderness score for each trope based on the number of pronouns and gendered terms. The image on the left summarizes their results very nicely.
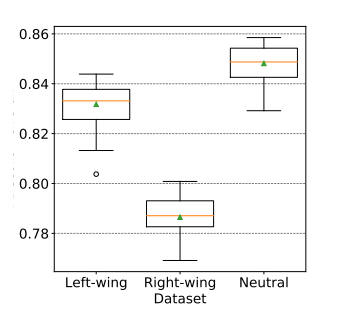
Another paper by Wich et al. analyzed the effect of politically biased data on hate speech classification. They created three data splits. Each split had non-offensive data along with left-leaning in one, right-leaning, and neutral in others. They found a significant performance difference between these splits. Additionally, they visualize the importance of tokens for hate speech classification as a step towards explainability.
🔥Fair Embedding Engine (FEE)🔥, introduced by Kumar et al., is a library for analyzing and mitigating gender bias in word embeddings.
FEE combines various state of the art techniques for quantifying, visualizing and mitigating gender bias in word embeddings under a standard abstraction.
TL;DR
A one-two liner summary of the papers 😇
Discovery of Bias
- Multi-Dimensional Gender Bias Classification — A more expressive and nuanced take on gender bias by breaking them into three aspects.
- Unsupervised Discovery of Implicit Gender Bias — A classifier that predicts gender bias in comments while controlling for the effects of observed confounding variables such as the original text, as well as latent confounding variables like authors traits and overt signals.
- Detecting Independent Pronoun Bias with Partially-Synthetic Data Generation — Masked language model-based sentence generation method to measure pronoun detection biases in language models.
- Type B Reflexivization as an Unambiguous Testbed for Multilingual Multi-Task Gender Bias — A multilingual, multitask dataset to investigate biasness via specific linguistic phenomena.
- Exploring the Linear Subspace Hypothesis in Gender Bias Mitigation — They show that gender subspace is indeed linear.
- We Can Detect Your Bias: Predicting the Political Ideology of News Articles — A dataset and a training mechanism such that the classifier learns to associate bias with text rather than the source.
- Detecting Media Bias in News Articles using Gaussian Bias Distributions — Detecting political bias in a text and an additional analysis of how sentence position and other article attribute correlates with bias.
- Analyzing Political Bias and Unfairness in News Articles at Different Levels of Granularity — Answers the question of how political bias manifests itself linguistically. To do so, they employ an RNN based classifier and reverse feature analysis to find bias patterns.
- Viable Threat on News Reading: Generating Biased News Using Natural Language Models — A LM based model to generate politically biased news (i) from scratch including titles and other metadata, and (ii) changing the bias of a given article.
- Weakly Supervised Learning of Nuanced Frames for Analyzing Polarization in News Media — Fifteen broad frames to analyze how issues are framed in news media are not nuanced enough. Proposes a three-step approach to add more fine-grained subframes.
- Identifying and Measuring Annotator Bias Based on Annotators’ Demographic Characteristics — The demography of annotator affects annotation and a classifier trained on corpus by one annotator demographics shows deterioration tested on the test same data when annotated by different demographics. They employ metadata from sources to identify different demographics.
- Investigating Annotator Bias with a Graph-Based Approach — Similar to above but they use cluster detection algorithms to identify different demographics.
- UNQOVERing Stereotyping Biases via Underspecified Questions — An approach to quantify bias in QA models via under specified questions while taking care of other reasoning errors.
- CrowS-Pairs: A Challenge Dataset for Measuring Social Biases in Masked Language Models — A dataset consisting of 1508 examples, with each example containing two sentences with one being more stereotyping when compared to other.
- LOGAN: Local Group Bias Detection by Clustering — Corpus level bias evaluation doesn’t paint the complete picture of biasness. They propose a new mechanism of clustering dataset, which groups similar examples together. At the same time, the cluster showcases some local bias.
Mitigating Bias aka Debiasing
- Mitigating Gender Bias for Neural Dialogue Generation with Adversarial Learning — A disentanglement model alongside an adversarial learning framework to generate responses with unbiased gender features and without biased gender features.
- Queens are Powerful too: Mitigating Gender Bias in Dialogue Generation — Examines gender bias present in the dialogue corpus and propose debiasing methods such as counterfactual data augmentation, positive-bias data collection, and special token to control the generated response’s genderedness.
- Towards Controllable Biases in Language Generation — An adversarial trigger based mechanism to influence the bias polarity of text generated.
- Reducing Unintended Identity Bias in Russian Hate Speech Detection — Hate speech detection triggers due to certain words that are not toxic but serve as triggers for the classifier due to model caveats. They propose to generate examples using LM trained on normative Russian text alongside word dropout techniques to circumvent it.
- Mitigating Gender Bias in Machine Translation with Target Gender Annotations — An approach where the source words are annotated with target gender, so that translation between non-grammatical gender to gender ones improves.
- Nurse is Closer to Woman than Surgeon? Mitigating Gender-Biased Proximities in Word Embeddings — Minimize the projection of gender-biased word vectors on the gender direction and at the same time reduces the semantic similarity with neighboring word vectors having illicit proximities.
- Neutralizing Gender Bias in Word Embeddings with Latent Disentanglement and Counterfactual Generation: An Encoder-Decoder framework that disentangles a latent space of a given word embedding into two encoded latent spaces: the first part is the gender latent space, and the second part is the semantic latent space that is independent of the gender information. Then employs counterfactual generation to generate gender-neutral embeddings.
- Debiasing knowledge graph embeddings — adversarial loss-based training mechanism to de-bias knowledge graph embeddings with minimum changes in the downstream accuracy and training time.
- PowerTransformer: Unsupervised Controllable Revision for Biased Language Correction — A GPT transformer-based mechanism to rewrite text using controlled tokens to remove potentially undesirable bias present in the text. They use reconstruction and paraphrasing objective to overcome the absence of parallel training data.
Miscellaneous
- Is Wikipedia succeeding in reducing gender bias? Assessing changes in gender bias in Wikipedia using word embeddings — Train embeddings at multiple snapshots of Wikipedia and see how they perform over WEAT and other in-depth analyses.
- Analyzing Gender Bias within Narrative Tropes — An analysis of gender bias in TV trope content by assigning genderdness scores via counting the number of pronouns and gendered words in their description and associated content.
- Impact of politically biased data on hate speech classification — Politically biased data can affect hate speech classification significantly.
- Fair Embedding Engine: A Library for Analyzing and Mitigating Gender Bias in Word Embeddings — A library which combines various state of the art techniques for quantifying, visualizing, and mitigating gender bias in word embeddings under a standard abstraction.
Datasets
A list of datasets which were proposed in the papers described above.
With the advent of more challenge datasets and methods to discover and mitigate biases in an unsupervised and supervised manner. I believe we have just started to scratch the surface of the problem.
Check twitter for updates on EACL@2021 and NAACL@2021. You can find more information about me, including contact information, here.